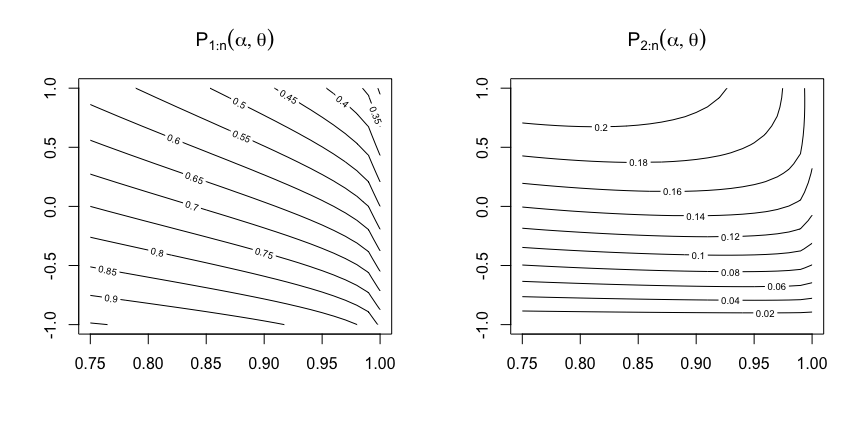
Inverse Gaussian
\(f(x|\mu,\lambda) = \left(\frac{\lambda}{2\pi x^3}\right)^{1/2} \exp\left(\frac{-\lambda (x-\mu)^2}{2 \mu^2 x}\right), x \in (0, \infty)\)
- Continuous distribution
- Not a true “inverse”
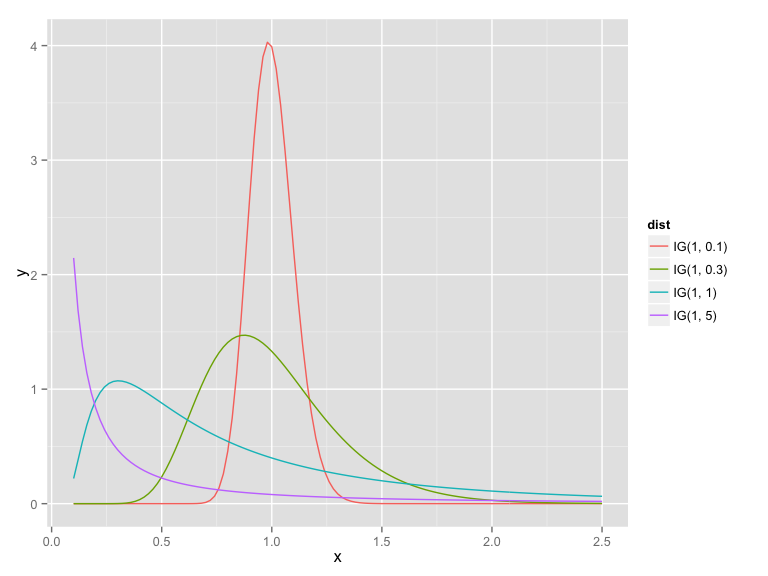
Inverse Gaussian–Poisson model
\(e^{\alpha \sqrt{(1 -\theta)}} \sqrt{ \frac{2 \alpha}{\pi}} \frac{(\frac{1}{2} \alpha \theta)^r}{r!} K_{r - \frac{1}{2}}(\alpha)\)
- \(K_y\) third kind modified Bessel function
- Mixture of a discrete distribution with a continuous distribution
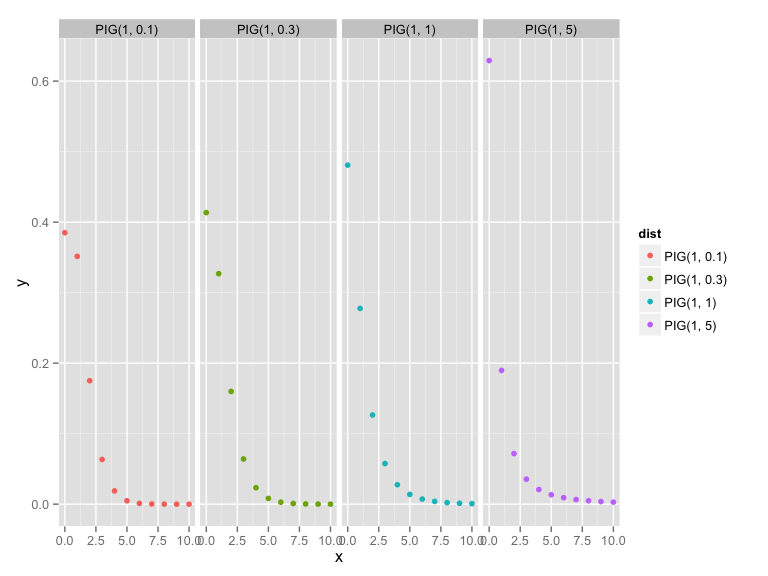
truncated Inverse Gaussian–Poisson model
- No words written 0 times
- A left truncation in zero needed
- Conditional probability
\[P(X = k | X > 0) = \frac{P(X = k \cap X> 0)}{1 - P(X = 0)}\]
gamlss.tr package
library("gamlss.tr")
trun.d(par = 0, family = "PIG", type = "left")
?trun.p; ?trun.q, ...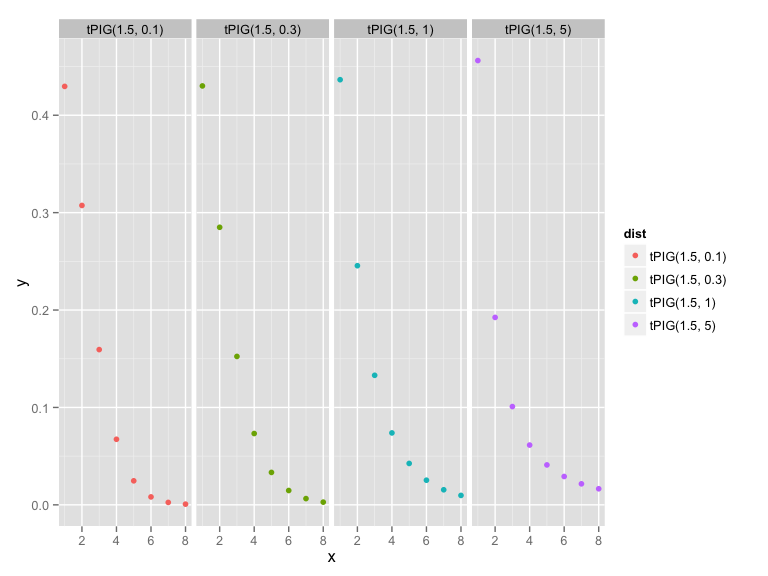
Extended truncated Inv..
- Extend parametric space \(\alpha \in (-1, 0)\)
- Extended version = not extended if \(\alpha \geq 0\)
- Recurrent function for calculating the model